
OpenAI (GPT-3.5)
La capacidad de GPT-3 para procesar y comprender el lenguaje humano le permite generar respuestas que son muy cercanas a las que un ser humano podría ofrecer en una conversación real. Además, GPT-3 tiene la capacidad de aprender de las interacciones con los usuarios y ajustar sus respuestas en consecuencia, mejorando así su capacidad de respuesta a medida que se usa.
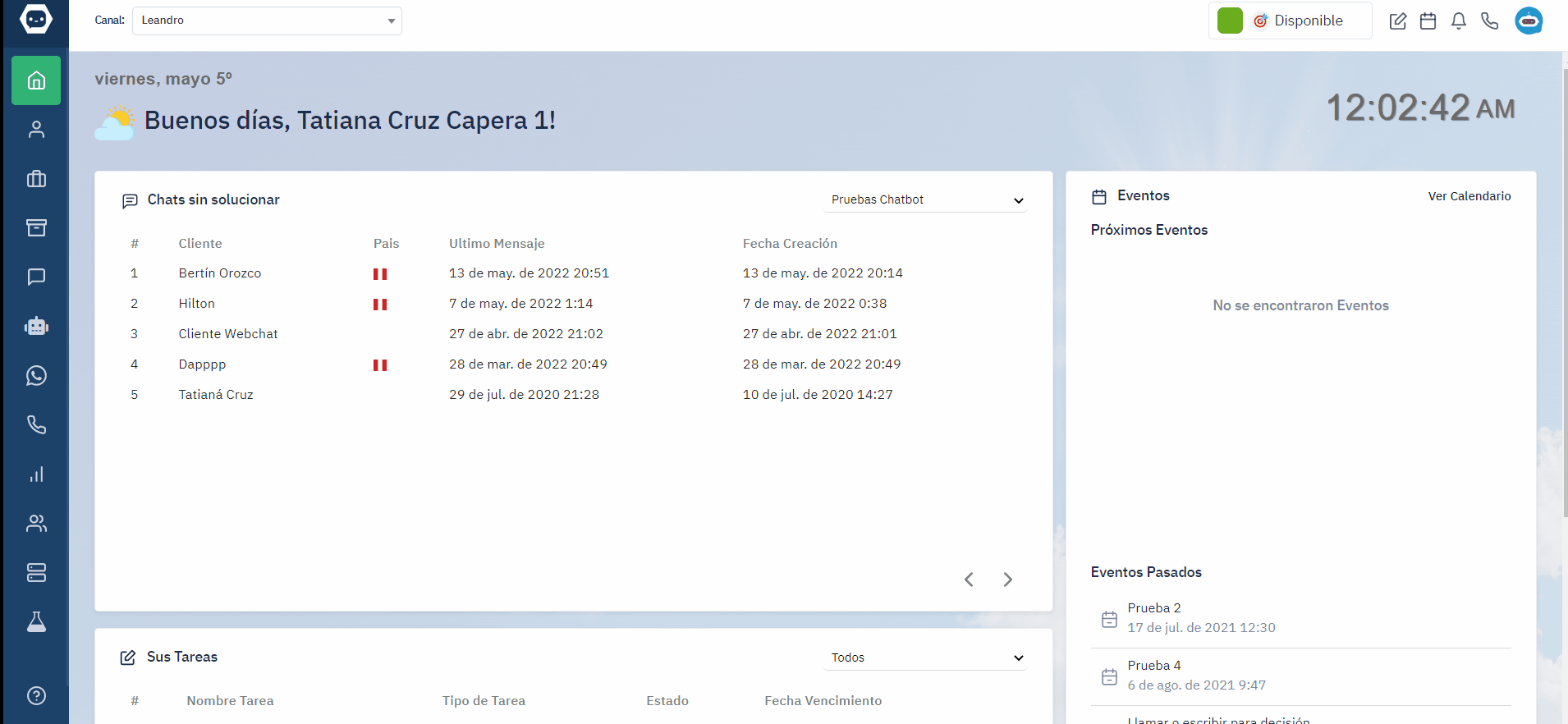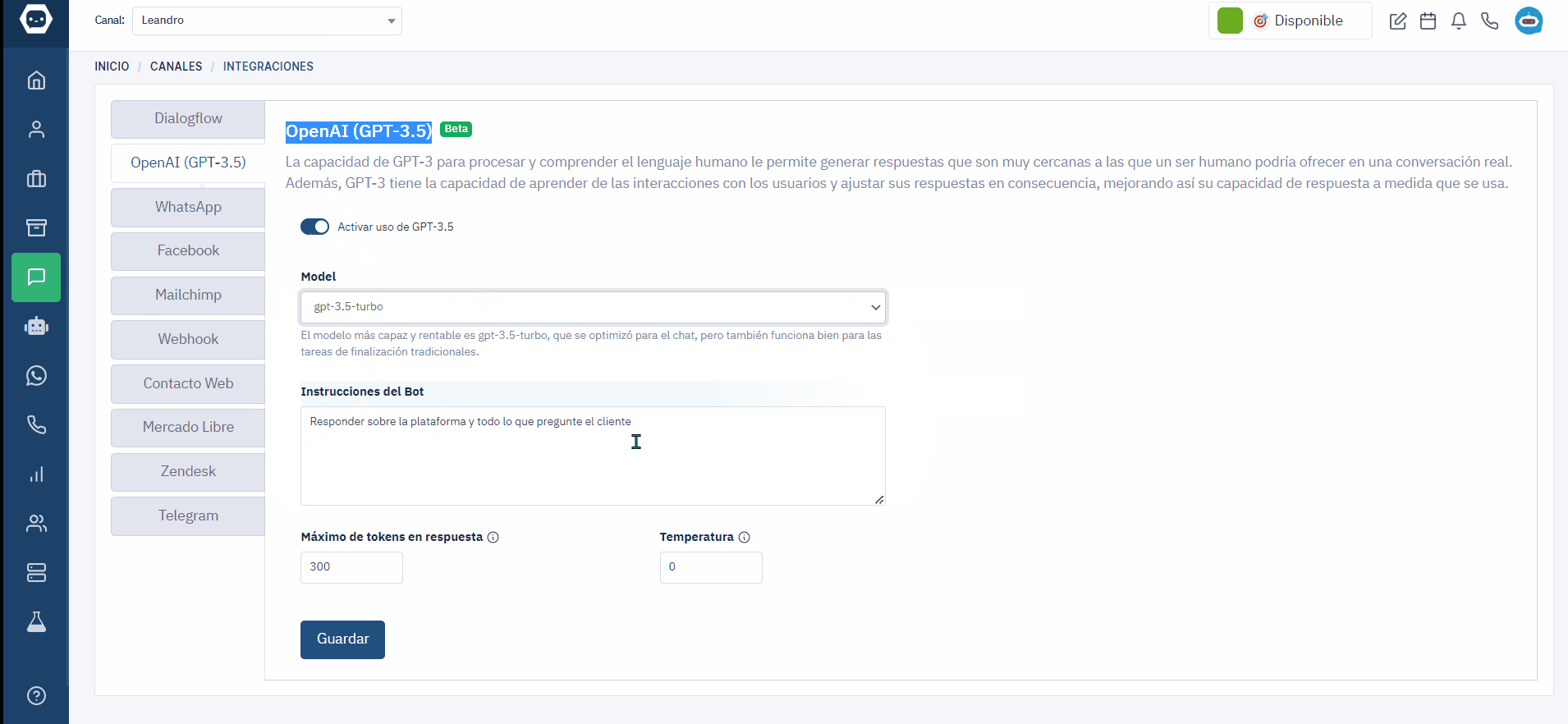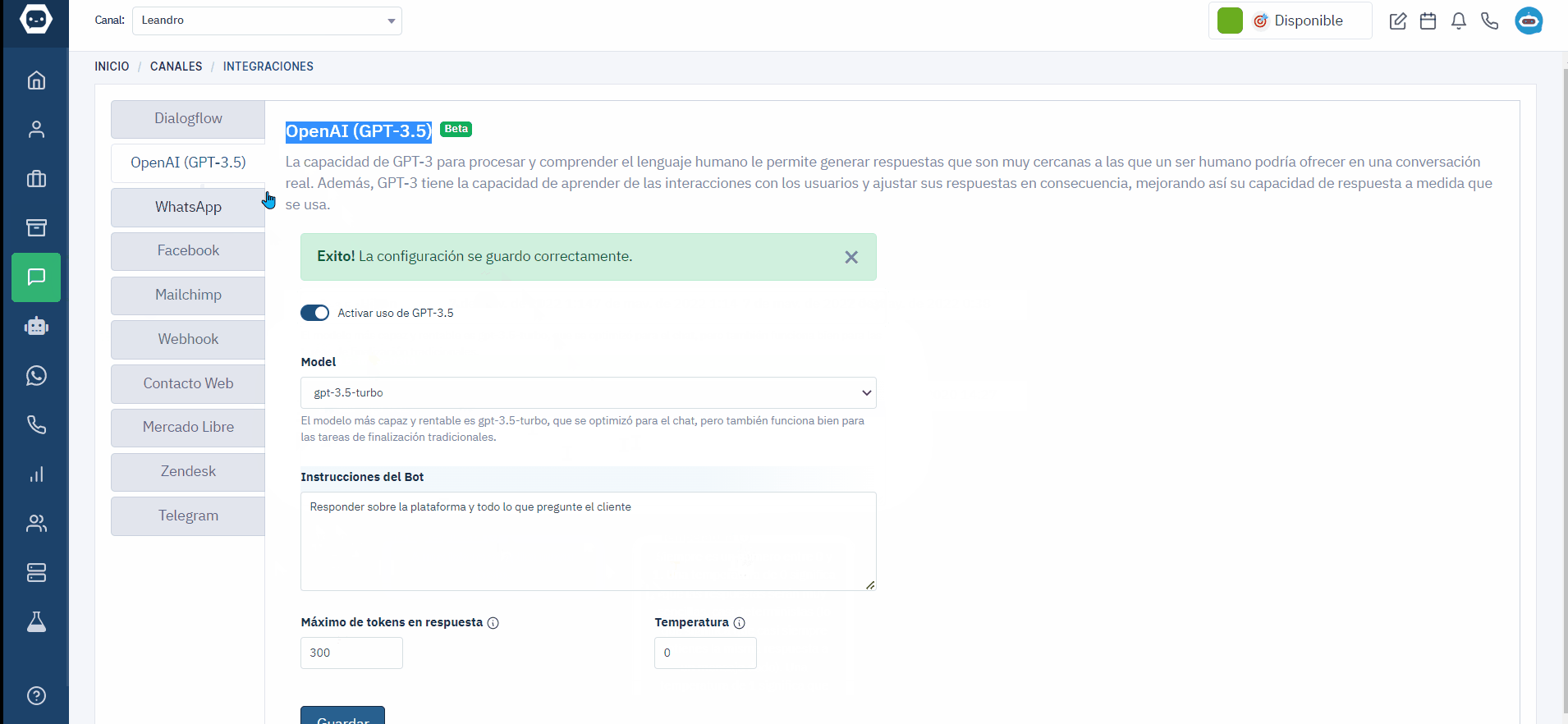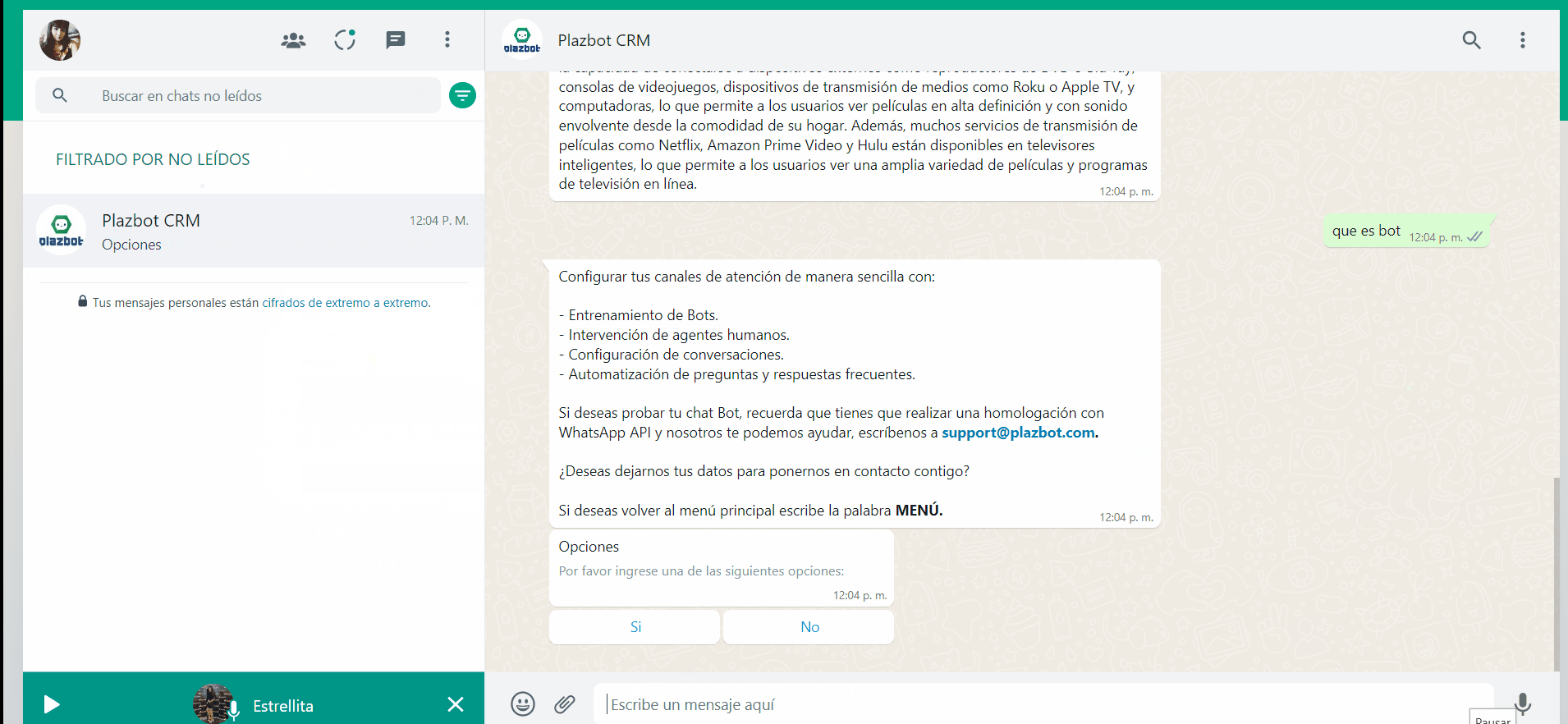
Activar uso de GPT-3.5
Cuando se activa este botón, ChatGPT responderá en situaciones en las que las respuestas del bot no cumplan con los criterios esperados o no sean lo suficientemente claras. Esto se conoce como "fallback" y el bot proporcionará una respuesta alternativa para abordar la situación.
No más Fallback
Model
La elección del modelo en ChatGPT determina la complejidad de las respuestas y su costo asociado. Para respuestas simples y económicas, se recomienda utilizar modelos más pequeños, mientras que para respuestas complejas y de alta calidad, es preferible optar por modelos más grandes y avanzados. La selección depende de tus necesidades específicas y los recursos disponibles.
gpt-3.5-turbo
Instrucciones del Bot
Aquí puedes proporcionar instrucciones sobre cómo quieres que el bot de ChatGPT funcione. Por ejemplo, puedes hacer preguntas directas, solicitar información específica o pedir al bot que realice una tarea en particular. Asegúrate de ser claro y específico al dar las instrucciones para obtener la respuesta deseada. También es útil proporcionar cualquier contexto relevante que pueda ayudar al bot a comprender mejor tus instrucciones. Recuerda que el bot utiliza técnicas de procesamiento de lenguaje natural y aprendizaje automático para interpretar tus instrucciones y generar respuestas coherentes.
Eres un agente de plazbot.com te llamas Leandro y debes responder sobre la plataforma y todo lo que pregunte el cliente
Máximo de tokens en respuesta
Para un uso óptimo de ChatGPT, se recomienda limitar las instrucciones a un máximo de 200 a 300 tokens.
Los tokens son unidades más pequeñas en las que se divide el texto antes de ser procesado por el modelo de Chat GPT. Cada token consume recursos computacionales, y los modelos tienen un límite en la cantidad de tokens que pueden procesar en una consulta. Por lo tanto, al hacer preguntas a Chat GPT, es importante considerar la longitud de la pregunta y el contexto dentro de los límites de tokens del modelo para obtener respuestas coherentes y completas.
Temperatura
La Temperatura 0 indica que las respuesta serán sencillas
la Temperatura 1 indica que las respuestas pueden variar
La temperatura en la consulta de Chat GPT es un parámetro que influye en la aleatoriedad y la diversidad de las respuestas generadas. Una temperatura baja produce respuestas más predecibles y coherentes, mientras que una temperatura alta genera respuestas más variadas y sorprendentes. La elección de la temperatura depende de si se busca coherencia o creatividad en las respuestas generadas por el modelo.
Updated 12 months ago