> ## Documentation Index
> Fetch the complete documentation index at: https://docs.plazbot.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Modelos del Agente
> Agregar modelos al Agente de IA
Este documento describe cómo puedes configurar diferentes proveedores de IA para tu agente, permitiéndote trabajar con OpenAI, Claude (Anthropic) y Gemini (Google) según tus necesidades.
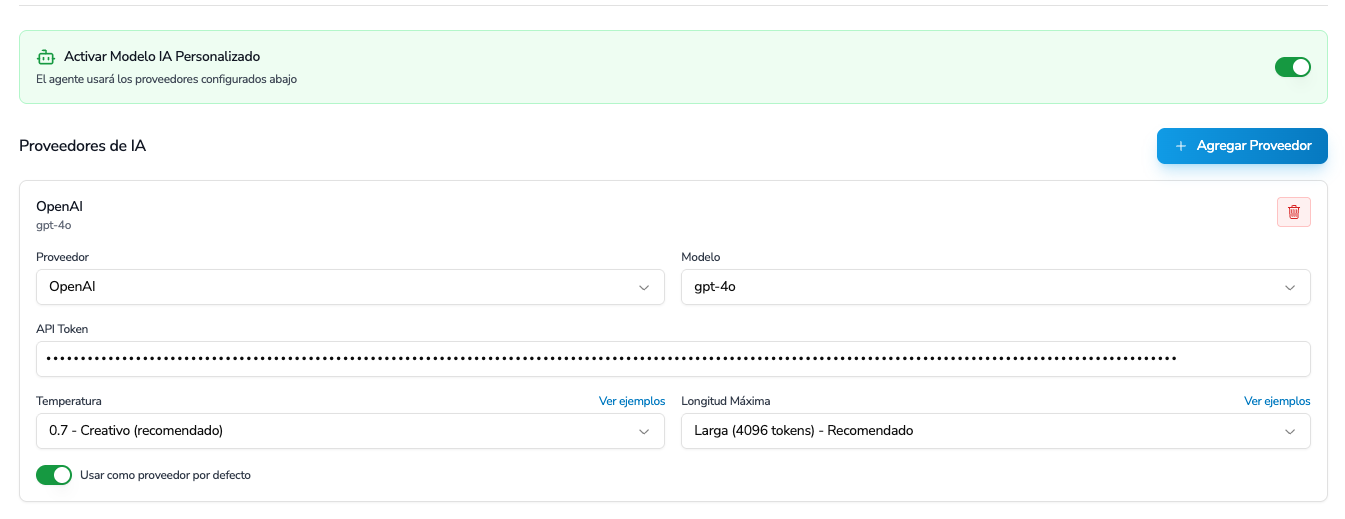 ### Configuración
Por defecto, todos los agentes en Plazbot utilizan el token de OpenAI configurado en tu workspace. Sin embargo, puedes habilitar la **Configuración Personalizada de IA** para:
* Usar diferentes proveedores de IA (OpenAI, Claude, Gemini)
* Configurar modelos específicos para cada proveedor
* Ajustar parámetros como temperatura y longitud de respuesta
* Usar tus propios tokens de API para cada proveedor
* Tener múltiples proveedores configurados con uno por defecto
**Importante:** Debes agregar al menos un proveedor de IA después de activar la configuración personalizada. Si el array está vacío, el sistema usará la configuración por defecto del workspace.
### Proveedor de IA
Cada proveedor requiere la siguiente información:
**Campos Obligatorios**
| Campo | Descripción |
| ------------- | ------------------------------------------ |
| **Proveedor** | Selecciona entre OpenAI, Claude o Gemini |
| **Modelo** | Modelo específico del proveedor a utilizar |
| **API Token** | Token de autenticación del proveedor |
**Campos Opcionales**
| Campo | Descripción | Valor Recomendado |
| ------------------------- | ----------------------------------------------- | ----------------- |
| **Temperatura** | Controla la creatividad de las respuestas (0-2) | 0.7 |
| **Longitud Máxima** | Máximo de tokens en la respuesta | 4096 |
| **Proveedor por defecto** | Define cuál proveedor usar si tienes varios | Activar en uno |
### Temperatura
La temperatura controla cuán creativas o predecibles serán las respuestas de la IA:
| Valor | Comportamiento | Casos de Uso |
| ------------- | ---------------------------- | ------------------------------------ |
| **0 - 0.3** | Muy consistente y predecible | Soporte técnico, respuestas precisas |
| **0.5 - 0.7** | Balance ideal | Uso general, atención al cliente |
| **1.0 - 1.5** | Creativo y variado | Marketing, contenido creativo |
| **1.5 - 2.0** | Muy creativo | Escritura creativa, brainstorming |
**Ejemplos prácticos:**
**Pregunta:** "¿Cuál es el proceso para resetear mi contraseña?"
**Respuesta (Temperatura 0):**
"Para resetear tu contraseña sigue estos pasos:
1. Haz clic en 'Olvidé mi contraseña'
2. Ingresa tu email registrado
3. Revisa tu correo y haz clic en el enlace
4. Crea tu nueva contraseña"
*Nota: La respuesta será prácticamente idéntica cada vez.*
**Pregunta:** "¿Cómo puedo mejorar mi productividad?"
**Respuesta (Temperatura 0.7):**
"Aquí te dejo algunas estrategias efectivas:
* Usa la técnica Pomodoro (25 min trabajo, 5 min descanso)
* Prioriza tareas importantes al inicio del día
* Elimina distracciones durante bloques de trabajo
* Establece objetivos diarios claros"
*Nota: Respuestas útiles y variadas sin ser impredecibles.*
**Pregunta:** "Dame ideas para un eslogan de marca"
**Respuesta (Temperatura 1.5):**
"¡Aquí van algunas opciones creativas!
* 'Donde tu visión cobra vida'
* 'Innovación que inspira futuro'
* 'Tu éxito, nuestra pasión'
* 'Transformando sueños en realidad'
¿Te gustaría explorar algún estilo en particular?"
*Nota: Más creativo y variado en cada generación.*
### Longitud Máxima (Max Tokens)
Define el límite máximo de tokens que puede generar la IA en su respuesta:
| Valor | Longitud | Uso Recomendado |
| --------- | ------------------------------- | ----------------------- |
| **1024** | Corta (\~700 palabras) | Respuestas breves |
| **2048** | Mediana (\~1,400 palabras) | Explicaciones moderadas |
| **4096** | Larga (\~2,800 palabras) | Uso general |
| **8192** | Muy larga (\~5,600 palabras) | Análisis detallados |
| **16384** | Extra larga (\~11,200 palabras) | Documentos completos |
**Recomendación:** Usa 4096 tokens para la mayoría de casos. Es suficiente para respuestas completas sin consumir recursos innecesarios.
**Ejemplos prácticos:**
**Uso ideal:** Preguntas simples, confirmaciones, respuestas rápidas
**Ejemplo:** "¿Cuál es el horario de atención?"
"Nuestro horario es de lunes a viernes de 9:00 AM a 6:00 PM, y sábados de 10:00 AM a 2:00 PM."
**Uso ideal:** Explicaciones detalladas, tutoriales, consultas complejas
**Ejemplo:** "¿Cómo funciona su proceso de onboarding?"
"Nuestro proceso de onboarding consta de 5 fases:
1. **Registro inicial** - Completas tu perfil con información básica...
2. **Verificación** - Validamos tu identidad mediante...
3. **Configuración** - Personalizas tu espacio de trabajo...
4. **Capacitación** - Accedes a tutoriales interactivos...
5. **Lanzamiento** - Empiezas a usar la plataforma..."
**Uso ideal:** Análisis profundos, reportes, documentación técnica
**Ejemplo:** "Explícame todo sobre su arquitectura de seguridad"
*La respuesta incluiría múltiples secciones con detalles técnicos extensos sobre encriptación, autenticación, protocolos, compliance, etc.*
### Ejemplo de Configuración Múltiple
```json theme={null}
{
"customAIConfig": true,
"aiProviders": [
{
"provider": "openai",
"model": "gpt-4o",
"apiToken": "sk-proj-xxxxx",
"temperature": 0.7,
"maxTokens": 4096,
"isDefault": true
},
{
"provider": "claude",
"model": "claude-3-5-sonnet-20241022",
"apiToken": "sk-ant-xxxxx",
"temperature": 0.5,
"maxTokens": 8192,
"isDefault": false
},
{
"provider": "gemini",
"model": "gemini-1.5-flash",
"apiToken": "AIza-xxxxx",
"temperature": 0.7,
"maxTokens": 4096,
"isDefault": false
}
]
}
```
**Nota:** Solo un proveedor puede tener \`isDefault: true\`. Este será el que use el agente para responder consultas.
### Seguridad
* Nunca compartas tus tokens de API públicamente
* Rota tus tokens periódicamente
* Configura límites de gasto en las consolas de los proveedores
* Revisa logs de uso regularmente
### Mejores Prácticas
1. **Empieza con valores por defecto:** Usa temperature 0.7 y 4096 tokens
2. **Prueba antes de producción:** Experimenta con diferentes configuraciones
3. **Monitorea costos:** Revisa tu uso mensual en cada proveedor
4. **Documenta cambios:** Registra qué configuración funciona mejor para tu caso
5. **Usa modelos apropiados:** No uses modelos caros para tareas simples
**Tip Pro:** Para casos de uso específicos:
* **Atención al cliente:** GPT-4o o Claude Sonnet con temperatura 0.7
* **Contenido creativo:** GPT-4 con temperatura 1.0-1.5
* **Análisis técnico:** GPT-4o o Claude Opus con temperatura 0.3
* **Alto volumen/bajo costo:** GPT-3.5-turbo o Gemini Flash
### Configuración
Por defecto, todos los agentes en Plazbot utilizan el token de OpenAI configurado en tu workspace. Sin embargo, puedes habilitar la **Configuración Personalizada de IA** para:
* Usar diferentes proveedores de IA (OpenAI, Claude, Gemini)
* Configurar modelos específicos para cada proveedor
* Ajustar parámetros como temperatura y longitud de respuesta
* Usar tus propios tokens de API para cada proveedor
* Tener múltiples proveedores configurados con uno por defecto
**Importante:** Debes agregar al menos un proveedor de IA después de activar la configuración personalizada. Si el array está vacío, el sistema usará la configuración por defecto del workspace.
### Proveedor de IA
Cada proveedor requiere la siguiente información:
**Campos Obligatorios**
| Campo | Descripción |
| ------------- | ------------------------------------------ |
| **Proveedor** | Selecciona entre OpenAI, Claude o Gemini |
| **Modelo** | Modelo específico del proveedor a utilizar |
| **API Token** | Token de autenticación del proveedor |
**Campos Opcionales**
| Campo | Descripción | Valor Recomendado |
| ------------------------- | ----------------------------------------------- | ----------------- |
| **Temperatura** | Controla la creatividad de las respuestas (0-2) | 0.7 |
| **Longitud Máxima** | Máximo de tokens en la respuesta | 4096 |
| **Proveedor por defecto** | Define cuál proveedor usar si tienes varios | Activar en uno |
### Temperatura
La temperatura controla cuán creativas o predecibles serán las respuestas de la IA:
| Valor | Comportamiento | Casos de Uso |
| ------------- | ---------------------------- | ------------------------------------ |
| **0 - 0.3** | Muy consistente y predecible | Soporte técnico, respuestas precisas |
| **0.5 - 0.7** | Balance ideal | Uso general, atención al cliente |
| **1.0 - 1.5** | Creativo y variado | Marketing, contenido creativo |
| **1.5 - 2.0** | Muy creativo | Escritura creativa, brainstorming |
**Ejemplos prácticos:**
**Pregunta:** "¿Cuál es el proceso para resetear mi contraseña?"
**Respuesta (Temperatura 0):**
"Para resetear tu contraseña sigue estos pasos:
1. Haz clic en 'Olvidé mi contraseña'
2. Ingresa tu email registrado
3. Revisa tu correo y haz clic en el enlace
4. Crea tu nueva contraseña"
*Nota: La respuesta será prácticamente idéntica cada vez.*
**Pregunta:** "¿Cómo puedo mejorar mi productividad?"
**Respuesta (Temperatura 0.7):**
"Aquí te dejo algunas estrategias efectivas:
* Usa la técnica Pomodoro (25 min trabajo, 5 min descanso)
* Prioriza tareas importantes al inicio del día
* Elimina distracciones durante bloques de trabajo
* Establece objetivos diarios claros"
*Nota: Respuestas útiles y variadas sin ser impredecibles.*
**Pregunta:** "Dame ideas para un eslogan de marca"
**Respuesta (Temperatura 1.5):**
"¡Aquí van algunas opciones creativas!
* 'Donde tu visión cobra vida'
* 'Innovación que inspira futuro'
* 'Tu éxito, nuestra pasión'
* 'Transformando sueños en realidad'
¿Te gustaría explorar algún estilo en particular?"
*Nota: Más creativo y variado en cada generación.*
### Longitud Máxima (Max Tokens)
Define el límite máximo de tokens que puede generar la IA en su respuesta:
| Valor | Longitud | Uso Recomendado |
| --------- | ------------------------------- | ----------------------- |
| **1024** | Corta (\~700 palabras) | Respuestas breves |
| **2048** | Mediana (\~1,400 palabras) | Explicaciones moderadas |
| **4096** | Larga (\~2,800 palabras) | Uso general |
| **8192** | Muy larga (\~5,600 palabras) | Análisis detallados |
| **16384** | Extra larga (\~11,200 palabras) | Documentos completos |
**Recomendación:** Usa 4096 tokens para la mayoría de casos. Es suficiente para respuestas completas sin consumir recursos innecesarios.
**Ejemplos prácticos:**
**Uso ideal:** Preguntas simples, confirmaciones, respuestas rápidas
**Ejemplo:** "¿Cuál es el horario de atención?"
"Nuestro horario es de lunes a viernes de 9:00 AM a 6:00 PM, y sábados de 10:00 AM a 2:00 PM."
**Uso ideal:** Explicaciones detalladas, tutoriales, consultas complejas
**Ejemplo:** "¿Cómo funciona su proceso de onboarding?"
"Nuestro proceso de onboarding consta de 5 fases:
1. **Registro inicial** - Completas tu perfil con información básica...
2. **Verificación** - Validamos tu identidad mediante...
3. **Configuración** - Personalizas tu espacio de trabajo...
4. **Capacitación** - Accedes a tutoriales interactivos...
5. **Lanzamiento** - Empiezas a usar la plataforma..."
**Uso ideal:** Análisis profundos, reportes, documentación técnica
**Ejemplo:** "Explícame todo sobre su arquitectura de seguridad"
*La respuesta incluiría múltiples secciones con detalles técnicos extensos sobre encriptación, autenticación, protocolos, compliance, etc.*
### Ejemplo de Configuración Múltiple
```json theme={null}
{
"customAIConfig": true,
"aiProviders": [
{
"provider": "openai",
"model": "gpt-4o",
"apiToken": "sk-proj-xxxxx",
"temperature": 0.7,
"maxTokens": 4096,
"isDefault": true
},
{
"provider": "claude",
"model": "claude-3-5-sonnet-20241022",
"apiToken": "sk-ant-xxxxx",
"temperature": 0.5,
"maxTokens": 8192,
"isDefault": false
},
{
"provider": "gemini",
"model": "gemini-1.5-flash",
"apiToken": "AIza-xxxxx",
"temperature": 0.7,
"maxTokens": 4096,
"isDefault": false
}
]
}
```
**Nota:** Solo un proveedor puede tener \`isDefault: true\`. Este será el que use el agente para responder consultas.
### Seguridad
* Nunca compartas tus tokens de API públicamente
* Rota tus tokens periódicamente
* Configura límites de gasto en las consolas de los proveedores
* Revisa logs de uso regularmente
### Mejores Prácticas
1. **Empieza con valores por defecto:** Usa temperature 0.7 y 4096 tokens
2. **Prueba antes de producción:** Experimenta con diferentes configuraciones
3. **Monitorea costos:** Revisa tu uso mensual en cada proveedor
4. **Documenta cambios:** Registra qué configuración funciona mejor para tu caso
5. **Usa modelos apropiados:** No uses modelos caros para tareas simples
**Tip Pro:** Para casos de uso específicos:
* **Atención al cliente:** GPT-4o o Claude Sonnet con temperatura 0.7
* **Contenido creativo:** GPT-4 con temperatura 1.0-1.5
* **Análisis técnico:** GPT-4o o Claude Opus con temperatura 0.3
* **Alto volumen/bajo costo:** GPT-3.5-turbo o Gemini Flash